
Der Online-Handel boomt. Damit steigt die Anzahl der angebotenen Produkte und Dienstleistungen im E-Commerce und die im Hintergrund stehenden Daten. Aus diesem Grund benötigen Unternehmen hochwertige und einzigartige Produkttexte in immer größerem Umfang. Die Erstellung der Produktbeschreibungen ist notwendig und zählt gleichzeitig zu den größten organisatorischen, manuellen und finanziellen Herausforderungen für den Online-Handel.
Nähern sich die Unternehmen dem Thema Produkttexte jedoch vorurteilsfrei, dann wird schnell deutlich, was hochwertige Produktbeschreibungen bewirken:
- Direkter Einfluss auf die Conversion im Kaufprozess
- Geringere Anzahl an Retouren
- Höhere Sichtbarkeit in Suchmaschinen
- Mehr Traffic
- Reduzierter Aufwand für Kundenrückfragen
- Positive Produkt- und Kundenerfahrung und eine damit einhergehende Kundenbindung
Unter Berücksichtigung dieser Punkte lohnt sich die Investition in qualitativ hochwertige Produktbeschreibungen. Insbesondere Produkttexte, die kurzfristig erstellt werden müssen, sollten mehr Beachtung erhalten, wie Beschreibungen zu saisonalen Produkten, Langläufern oder neuen Kollektionen. Die Herausforderung ist es, die große Masse an Texten zu bewältigen und gleichzeitig immer aktuell zu halten – und das Ganze in einem finanziell vertretbaren Rahmen. Hier kommt die automatisierte Erstellung von Produkttexten, die Natural Language Generation (NLG), ins Spiel.
Das PIM-System verbessert die Qualität deiner Produktdaten
NLG funktioniert nur mit einer guten Datenbasis. Voraussetzung dafür ist, dass überhaupt Daten vorhanden sind, und dass sie stetig gepflegt werden. Daten können auf unterschiedliche Weise gesammelt, archiviert und genutzt werden. Durch ein PIM-System (Produkt-Informations-Management-System) kann die Qualität und Genauigkeit der Daten verbessert werden, was zur Optimierung von nachfolgenden Geschäftsprozessen führt. Das PIM-System ist ein zentraler Ort für alle projektrelevanten Informationen, Spezifikationen und digitalen Dateien. Aus einem PIM-System können die relevanten Produktinformationen für Online-Shops an unzählige Kanäle exportiert werden.
Datenqualität und -vollständigkeit beeinflussen Qualität automatisiert erstellter Texte
Bei der Textautomatisierung hat die Datenqualität einen entscheidenden Einfluss auf die Qualität der Ergebnisse. Die Basis des Erfolgs im Handel mit Produkten und Dienstleistungen sind hochwertige Produktdaten. Produktinformationen werden von Herstellern bereitgestellt und müssen vom Handel für die Zielgruppe aufbereitet werden. Teilweise sind hier Schwachstellen vorhanden. Herstellerangaben erfüllen oftmals rechtliche Anforderungen, sind aber für Laien nicht immer verständlich. Sie müssen in der Regel also veredelt werden. Es gilt: Content is King. Das heißt, je genauer und zielgerichteter die Daten sind, desto besser. Die Vollständigkeit und Qualität der Produktdaten sind entscheidend für ein positives Einkaufserlebnis.
Auch interessant: So machst du deine Produktdaten fit: 2 Experten geben Tipps
Data Quality Rules erleichtern Kontrolle der Datenqualität
Ein PIM-System hilft dabei, die grundlegende Datenqualität und Datenstruktur technisch sicherzustellen. Es ermöglicht durch das Festlegen von Vorgabewerten und Pflichtfeldern direkten Einfluss auf die Datenqualität zu nehmen. Diese Vorgaben sind Bestandteil weitreichender Data Quality Rules, die innerhalb eines PIM-Systems konfiguriert werden können, wodurch eine Steuerung und Überwachung der Datenqualität erleichtert wird. Ein gutes PIM ist etwa in der Lage, aus bestehenden Attributen zusätzliche Attribute zu generieren.
In der Praxis hat sich jedoch gezeigt, dass die Qualität der Produktdaten bei vielen geplanten Projekten noch nicht ausreicht, um die Potenziale der Textautomatisierung mittels NLG voll auszuschöpfen und die gewünschte Textqualität zu erreichen. In diesen Fällen sind unterschiedliche Szenarien denkbar, wie dennoch mit der automatisierten Texterstellung begonnen werden kann. Beispielsweise können die Regelwerke für die Textautomatisierung parallel zu der stattfindenden Datenaufbereitung angelegt werden. Ebenso sind mehrstufige Vorgehen vorstellbar. Dabei werden in einem ersten Schritt die zur Verfügung stehenden Attribute genutzt und später, sobald sie verfügbar sind, weitere Attribute in die Texte hinzugefügt.
Daten sind wichtig. Aber es ist erst die Geschichte, die du mit ihnen erzählst, die Daten wirklich wertvoll machen. Wie du das Beste aus deinen Daten rausholst, wird in folgendem AX-Meetup diskutiert:
Die Notwendigkeit der Vollständigkeit, Verfügbarkeit, Granularität und Konsistenz der Produktdaten
Um aus Produktdaten automatisierte Texte, wie beispielsweise Produktbeschreibungen, erstellen zu können, müssen die Daten: 1. vollständig, 2. verfügbar, 3. granular und 4. konsistent verfügbar sein.
1. Vollständigkeit der Daten
Bei der automatisierten Texterstellung ist es essentiell dafür zu sorgen, dass die dafür notwendigen Daten bzw. Produkteigenschaften komplett erfasst werden. Es ist nicht erforderlich, jeden Aspekt eines Produkts zu erfassen. Entscheidend ist vielmehr, die für die Betextung relevanten Attribute zu benennen und ein entsprechendes Struktursystem zu entwerfen. Dieses Struktursystem kann anschließend in ein Datenmodell innerhalb eines PIM-Systems überführt werden.
2. Verfügbarkeit der Daten
Die Datenquelle spielt oberflächlich betrachtet für die Betextung mit einem NLG-System keine große Rolle. Es ist unerheblich, ob die strukturierten Daten aus einer Tabelle ausgelesen werden oder via REST-API direkt mit entsprechenden Quellsystemen kommuniziert wird. In einem vollautomatisierten Workflow hingegen ist es erforderlich, eine führende Datenquelle zu bestimmen, die die Produktdaten bereitstellt. In der Regel ist dies das PIM-System, das beispielsweise mittels Connector angebunden wird.
3. Granularität der Daten
Granularität bedeutet, dass die vorliegenden Attribute möglichst getrennt voneinander erfasst werden. Diese Voraussetzung ist nicht nur für die Automatisierung der Produktbeschreibungen relevant, sondern trägt auch zu einer Verbesserung der Produktsuche bei. Sollten die Produktdaten nicht ausreichend granular vorliegen, können diese in einem Zwischenschritt aufgeteilt und strukturiert werden, wodurch die Produktdaten anschließend für die Automatisierung nutzbar sind.
4. Konsistenz der Daten
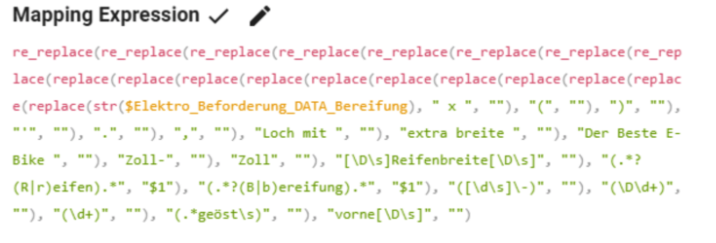
Der vierte wichtige Punkt ist die Konsistenz der gepflegten Produktdaten. Unterschiedliche Schreibweisen der gleichen Merkmalsausprägungen führen dazu, dass die Trainingserstellung erschwert wird, da diese Fehler entsprechend durch die NLG-Software abgefangen und korrigiert werden müssen. Eine konsistente Schreibweise von Merkmalsausprägungen kann zukünftig beispielsweise durch Vorgabewerte bei einzelnen Datenfeldern sichergestellt werden. Die Optimierung bereits vorhandener Produktdaten stellt ebenfalls eine Herausforderung dar. Merkmalsausprägungen kann zukünftig beispielsweise durch Vorgabewerte bei einzelnen Datenfeldern sichergestellt werden. Die Optimierung bereits vorhandener Produktdaten stellt ebenfalls eine Herausforderung dar.
Hohe Datenqualität durch systematisches Produktdaten-Onboarding
Wie kann effizient die notwendige Vollständigkeit, Verfügbarkeit, Granularität und Konsistenz der Produktdaten erreicht werden? Die Basis dafür ist ein systematisches Produktdaten-Onboarding, mit welchem die gewünschte hohe Datenqualität erreicht wird, um hochwertige Texte automatisiert generieren zu können.
Im Onboarding-Prozess sind bestimmte Schritte besonders relevant bezüglich der Datenqualität: Die Vollständigkeit der Daten kann im Schritt Attribut Mapping, also der kategoriespezifischen Zuordnung der Lieferanten-Attribute auf die PIM-Attribute, sichergestellt werden. Hier wird kontrolliert, ob die definierten Pflichtattribute pro Kategorie durch den Lieferanten geliefert wurden. Auch das Mappen der Lieferantenwerte auf die PIM-Vorgabewerte zeigt mögliche Lücken auf.
Auf Basis dieser beiden Onboarding-Schritte werden fehlende Produktinformationen identifiziert und können so zielgerichtet beim Lieferanten bzw. beim Hersteller nachgefordert werden. Möglich ist auch eine Anreicherung mit Inhalten von einem Content Provider, der kostenpflichtig Produktdaten und weitere Informationen zur Verfügung stellt.
Produktdaten-Verfügbarkeit abhängig vom Automatisierungsgrad des Onboardings
Die Verfügbarkeit der Produktdaten hängt vor allem vom Automatisierungsgrad des Onboardings ab - je automatisierter der Prozess, desto schneller können die Daten an das PIM übergeben und für die automatisierte Textgenerierung genutzt werden. Je offener die verwendeten PIM-Systeme bezüglich Datenimport und -export sind, desto einfacher können externe Onboarding-Systeme verwendet und der effiziente und problemlose Austausch der Daten gewährleistet werden.
Granularität der Daten durch Textextraktion
Um die Granularität der Produktdaten zu erhöhen, ist oft eine Textextraktion notwendig, da gewisse Attribute nicht strukturiert durch den Lieferanten zur Verfügung gestellt werden. In diesem Prozess werden aus semi-strukturierten Inhalten vom Hersteller, wie den Produkttiteln oder den unstrukturierten Produktbeschreibungen, die relevanten Attribute extrahiert. Die aus den Texten gewonnenen Attribute können dann beispielsweise für zusätzliche Filter im Onlineshop genutzt werden.
Konsistenz der Daten durch Vereinheitlichung von Werten
Die Konsistenz von Produktdaten kann im Normalisierungsschritt sichergestellt werden: Dabei werden die in den Daten vorhandenen Zahlen, Einheiten, Wertelisten oder Schreibweisen vereinheitlicht. Auch Abkürzungen können aufgelöst oder Synonyme in eine übereinstimmende Benennung umgewandelt werden.
Sind alle diese Schritte durchlaufen, sind die aufbereiteten Produktdaten in einer hochwertigen Qualität verfügbar und können in das PIM-System importiert und von dort aus für die weitere Nutzung verfügbar gemacht werden. Eine Onboarding-Plattform ist somit eine wertvolle Ergänzung zum PIM, um sicherzustellen, dass die Daten vollständig sowie in der erforderlichen Granularität und Konsistenz verfügbar sind.
Fazit
Zusammenfassend ist festzustellen, dass fehlende Granularität, Konsistenz und Vollständigkeit der Datenfelder dafür sorgen, dass die erstellten Trainings innerhalb der NLG-Lösung fehleranfällig, unnötig komplex und schwerer wartbar werden. Ist die Verfügbarkeit der Produktdaten nicht gewährleistet, kann keine Automatisierung erfolgen.
Das PIM-System nimmt in einer NLG-fähigen Systemlandschaft eine entscheidende Rolle ein. Als zentrale Datenquelle stellt es alle relevanten Produktdaten für die NLG-Software bereit und ermöglicht die Ausleitung in unterschiedliche Kanäle, wie beispielsweise den Online-Shop.
Über den Autor
hmmh ist Partner und Managed Service Provider von AX Semantics und hat diesen Artikel zum Thema gute Produktdaten aus einem PIM-System verfasst. Als Management Service Provider unterstützt hmmh Kunden mit einer Full-Service-Komponente. AX Semantics empfiehlt den Kunden hmmh, wenn externe Manpower benötigt wird.
Das Unternehmen ist führend im Bereich Connected Commerce: Vor mehr als 20 Jahren brachte hmmh den E-Commerce nach Deutschland. Seitdem prägt das Unternehmen die Entwicklungen in diesem Bereich. Für hmmh ist Connected Commerce die logische Fortsetzung des Multi-Channel-Business, in dem Kanäle zu Touchpoints werden und die Grenzen zwischen online und offline verschwinden - zu jeder Zeit, an jedem Ort und über alle Geräte hinweg, immer der richtige Content.